
LINE の Data Labs(データラボ)で自然言語処理に関連する技術に関わっている @overlast (佐藤 敏紀) です。この記事は、LINE Advent Calendar 2016 の 15 記事目です。
この記事をお読みの方には「LINE と自然言語処理って関係あるの?」と思われる方もいらっしゃる思います。
Data Labs ではデータ収集・解析基盤の開発や機械学習技術の適用だけでなく、自然言語処理に関する実用的な技術の開発・研究を、かなり真面目におこなっており、その成果によって弊社のお客様のお役に立つことは当然として、他社さまや研究者、学生さんにも広く貢献したいと考えております。
はじめに
今回は、私が作っている mecab-ipadic-NEologd とその効果について、このブログで一回も書いていなかったので書きます。
mecab-ipadic-NEologd は形態素解析エンジン MeCab と共に使う単語分かち書き辞書で、週2回以上更新更新され、新語・固有表現に強く、語彙数が多く、しかもオープンソース・ソフトウェアである という特徴があります。
この記事では、mecab-ipadic-NEologd の分書分類タスクにおける有効性を確認する実験をおこない、その結果として「安心して最新版の mecab-ipadic-NEologd を使って大丈夫」という結論を得たことについて書きました。
色々な方々が頑張って下さっているおかげで mecab-ipadic-NEologd は Kuromoji からも使える様になっており、川田さん(@hktechno)による 6 記事目、(Elasticsearch を検索エンジンとして利用する際のポイント)の記事に出てきた「Elasticsearch のすごいところは、大量のドキュメントの中から形態素解析や n-gram など自然言語的な解析を行った上で(略)」という部分にも関係してきます。
この記事は、自然言語処理が必要そうな仕事をなさっているエンジニアさんにオススメの記事ですので、最後まで読んで頂いたり、「新語や未知語が足りない問題」などで困っているお仲間にオススメして頂けると、とても嬉しいです。
例文:「彼女はペンパイナッポーアッポーペンと恋ダンスを踊った。」
形態素解析エンジン MeCab (メカブ) は日本語のテキストを解析する際に、「形態素」という普通の単語よりも少し細かい単位でそのテキストを区切ります。MeCab は形態素解析をする際に辞書を使っていて、IPADIC(アイピーエーディック) と UniDic(ユニディック) という名前の辞書が有名です。
まずは例文を MeCab + IPADIC で処理した結果を確認しましょう。私の環境ではこの様に出力されました。

「ペンパイナッポーアッポーペン」という曲名は「未知語(辞書に無い単語)」として処理されました。MeCab は未知語に読み仮名を勝手に付与しないので、簡単に未知語を見分けることができます。
ドラマのエンディングで新垣結衣さんらが披露したことで有名になったダンスの「恋ダンス」という通称は
- 恋
- ダンス
の様に、2つの IPADIC に採録されている名詞として分割されました。
- 助詞 :「は」「と」「を」
- 動詞 :「踊る」の連用形
- 助動詞 :「た」
などの名詞以外の形態素も得られました。
形態素解析時に固有名詞が分割されてしまう4つの理由
「ペンパイナッポーアッポーペン」や「恋ダンス」の様に、文字列からイメージできる実体が複数の人物間でほとんど同じであり、他の名詞と明確に区別可能な固有の呼び名になっている名詞を「固有名詞」と呼びます。国名、地名、建物名、店名、人名、グループ名、法人名、書籍名、曲名などは固有名詞になりやすいです。
MeCab + IPADIC によって固有名詞が複数の形態素に分割される理由は多々あるのですが、そのうち分かりやすい4つの理由を挙げます(詳しい解説は省略)。
- 理由1. IPADIC や UniDic は形態素解析のための辞書
- 理由2. IPADIC や UniDic は更新の頻度が低い(または更新停止状態)
- 理由3. 形態素解析と固有表現抽出は別の研究トピック
- 理由4. 未知語を検出するにはデータが必要
このような理由が今後も消えないことを前提として、固有名詞がバラバラになる問題を少しでも解決するためには、
- 形態素単位での単語分割にこだわらず、固有名詞を1単語として分割する
- 定期的に更新して、現実の状況を反映する
- よく使われる固有名詞にはあらかじめ対応する
- 未知語は見つかり次第対応する
という方針で分かち書き処理を改善するための言語資源を作り、さらに、この方針が悪影響を与えない様にするため、
- 既存の形態素解析の結果が実用上正しい時は尊重する
という状態を実現できれば良さそうだと考えました。
mecab-ipadic-NEologd を使いましょう
mecab-ipadic-NEologd は形態素解析用の辞書ではなく「単語分かち書き」用の辞書です。
この辞書を使って分割した際の単語の粒度が形態素になるか分からないので、単語分かち書きと呼んでいます。
mecab-ipadic-NEologd には以下のような4つの特徴があります。
- IPADIC では複数の形態素に分割されてしまう固有表現を採録
- 毎週 2 回以上更新
- Web上の言語資源を活用して更新時に新しい固有表現を随時追加
- ライセンスが Apache License, Version 2.0
更新時に追加されるのは以下の様なエントリです。
- ニュース記事から抽出した新語や固有名詞や未知語
- ネット上で流行した単語や慣用句やハッシュタグ
- 一般名詞/固有名詞/サ変接続名詞の表記ゆれ
- パターン生成した時間表現や数値表現
- Unicode 9.0 以下の絵文字
- 初期状態のスマホで入力できる顔文字
また、
- IPADIC に採録されていない副詞、形容詞、形容動詞、感動詞の追加
- SNS やブログ記事にありがちな崩れた表記の追加
- IPADIC に含まれるエントリが引き起こすエラー対策
なども行っています。
弱点は富豪的にディスクとメモリを使うこと(問題だと認識はしています)です。
MeCab + mecab-ipadic-NEologd で例文を単語分かち書きする
では、例文を MeCab + mecab-ipadic-NEologd で解析します。

MeCab + IPADIC の結果との違いは「ペンパイナッポーアッポーペン」と「恋ダンス」が固有名詞扱いになっているということです。
MeCab の辞書は単語の表層文字列以外に品詞情報や表層の原型、読み仮名などを得られます。
「ペンパイナッポーアッポーペン」の原型が「Pen-Pineapple-Apple-Pen」になっているのは重要です。実は「PPAP」というエントリにも原型が「Pen-Pineapple-Apple-Pen」なものが含まれているので、原型カラムを使えば『「ペンパイナッポーアッポーペン」も「PPAP」も「Pen-Pineapple-Apple-Pen」である』と同義語をまとめる処理を簡単に実現できます。
mecab-ipadic-NEologd の効果の高さは用途次第
mecab-ipadic-NEologd が効果的だった用途をいくつか例を挙げると
- テキストから特徴ベクトルを生成する
- 単語の分散表現(単語埋め込み)を使う
- テキストから大雑把に固有表現を抽出する
- 全文検索の結果を、よりクエリと一致させて改善する
- 任意の文字列の読み仮名を取得する
- 類似文字列の検索や、スペル訂正を自作する
などの場合に実際に有効でした。
より具体的な例を挙げると「文書分類」をする時は、学習時や評価時にテキストから特徴ベクトルを作成しますけど、mecab-ipadic-NEologd でテキストを分かち書きすると、辞書に大量の語彙が採録されていることと、採録されている固有表現は解析時に複数の形態素に分割されにくいことから、より高次元でより疎なベクトルが作成できることを期待できるので、効率良く学習できることを期待できます。
MeCab + mecab-ipadic-NEologd で最近のニュース記事をカテゴリ分類する
以下ではインターネット上のニュース記事をその内容にもとづいて、あらかじめ人間が用意したカテゴリに分類する実験をします。文書分類タスクにおける mecab-ipadic-NEologd の有効性を確認する以外に、この実験では以下の3点を確認したいと思います。1. 分かち書きに使用する辞書や、単語の単位の影響
- IPADIC(形態素) と UniDic(短単位の形態素) と mecab-ipadic-NEologd(固有表現は1単語) を使った場合に、どの程度結果が変わるかを確認する
2. 辞書に新語を追加することの影響
- mecab-ipadic-NEologd 自体や、これを更新することによる悪影響が無いことを確認する
3. 学習データを増やした時の影響
- 細かいカテゴリ粒度を使って文書分類を行う際に、mecab-ipadic-NEologd を使うことで学習データを雑に増量しても分類性能が急激に下がらないことを確認する
ニュース記事データの詳細
今回の実験において評価目的で使用させて頂いたデータは「Yahoo!ニュース」さんのデータです。
みなさんが同様の実験を再現するためのデータを入手するコストと、記事が分類されているカテゴリの質について考えた結果、様々なサイトの中からYahoo!ニュースさんを選びました(とても感謝しております)。
収集したデータの概要は以下のとおりです。
| 収集したサイト | Yahoo!ニュース |
|---|---|
| 収集手法 | 新着ニュース一覧から定期的に収集 |
| クロールした期間 | 2016/05/21(土)~2016/10/28(金) |
| クロールした記事数 | 計 539,524 記事 |
この収集したデータを学習データと評価データに分けます。その際に、学習データはデータ収集日の幅を1ヶ月ずつ増やして、今回は5ヶ月分まで作りました。
| セット名 | 使用するデータ収集期間 | 日数 | 記事数 |
|---|---|---|---|
| 学習データ1ヶ月分 | 2016-09-21(水) ~ 2016-10-20(木) | 30日間 | 101,203 |
| 学習データ2ヶ月分 | 2016-08-21(日) ~ 2016-10-20(木) | 61日間 | 204,952 |
| 学習データ3ヶ月分 | 2016-07-21(木) ~ 2016-10-20(木) | 92日間 | 305,272 |
| 学習データ4ヶ月分 | 2016-06-21(火) ~ 2016-10-20(木) | 122日間 | 407,242 |
| 学習データ5ヶ月分 | 2016-05-21(土) ~ 2016-10-20(木) | 153日間 | 511,413 |
| 評価データ | 2016-10-21(金) ~ 2016-10-28(金) | 8日間 | 28,111 |
収集した記事データの各記事には、大カテゴリ(計8種類)とその各カテゴリの下位にある小カテゴリ(計81種類)のラベルが付与されています。このラベルは記事収集時に、記事データのHTMLファイルから抽出しています。
分かち書きに使用した MeCab 用の辞書の詳細
収集したニュース記事を MeCab で分かち書きしますが、その際の辞書として以下の5種類を用意しました。
| 名前 | 解説 |
|---|---|
| IPADIC v2.7.0 | 配布されている IPADIC をインストールした |
| UniDic v2.1.2 | 配布されている UniDic をインストールした |
| NEologd 20160919 | 学習データ収集期間前の 2016/09/19 に更新 |
| NEologd 20161021 | 学習データ収集期間後の 2016/10/21 に更新 |
| NEologd 20161103 | 評価データ収集期間後の 2016/11/03 に更新 |
このようにすることで、
- そもそも mecab-ipadic-NEologd に意味はあるの?
- mecab-ipadic-NEologd で分かち書きして悪影響は無いの?
- mecab-ipadic-NEologd を週2回も更新することに意味はあるの?
などの典型的な疑問について考察する材料を得たいと考えました。
学習器と特徴ベクトルの作り方
学習器は LIBLINEAR を使用しました。LIBLINEAR で学習するときのパラメーターですが、今回は辞書やデータごとに最適なパラメーターを探すことが今回の目的ではありません。そこで、別の期間のデータと MeCab 用の辞書を用意して、事前に実験と相対的に同様なデータと辞書の関係を作って探索することにしました。その結果、「s=5, c=0.8, B=-1」という設定が比較対象の UniDic にとって総合的に有利だったのでそれを採用しました。
各ニュース記事のタイトルと本文を合わせて MeCab と任意の辞書の組み合わせで分かち書きして単語列にし、各記事の各単語の頻度を学習データ内における tf-idf 値に変換した後、その値を LIBSVM の svm-scale コマンドで 0 から1 の値にスケーリングした後で学習しています。
品詞情報を使った単語の取捨選択も事前に実験したのですが、全部の単語を使ったほうが全体の分類性能は向上したので、今回の実験でも単語の取捨選択をしていません。
評価データは学習データと同様にtf-idf 値に変換した後で、学習データをスケーリングした際に保存されたスケール尺度を使ってスケーリングしました。
大カテゴリに分類する実験
以上の様な設定で学習データ1ヶ月分を使い学習して、評価データを大カテゴリに分類した結果のF値のマクロ平均とマイクロ平均の表(自分のNL研の論文から引用)が以下です。

太字の値は他のすベての辞書による結果との符号検定の結果の P 値≦ 0.001 と なっており有意水準 0.001で有意でした。とはいえ、有意だ、とドヤ顔したいのではなくて、
- mecab-ipadic-NEologd を使ったときに少なくともニュース記事では悪影響が無さそう
- 更新して新語や未知語を追加することで、分類性能に対して前向きな変化を与えていそう
という2点が大雑把に分かったので、安心して最新の mecab-ipadic-NEologd を使える様になったのが良かった点だと考えています。
学習データの量の影響を調査する実験
とはいえ、上述の結果だけでは「そもそも mecab-ipadic-NEologd に意味があるの?」という疑問には答えきれていないので、今度は学習データの量の影響を調査する実験をします。設定は「大カテゴリに分類する実験」と同様ですが、異なる期間の複数の学習データセットを使っています。また、mecab-ipadic-NEologd については先程の実験で、最新版を使っても大丈夫そうでしたので「NEologd 20161103」だけを使いました。
異なる量の学習データから作ったモデルを使って、評価データを大カテゴリと小カテゴリに分類した結果のF値のマクロ平均とマイクロ平均の表(自分のNL研の論文から引用)が以下です。
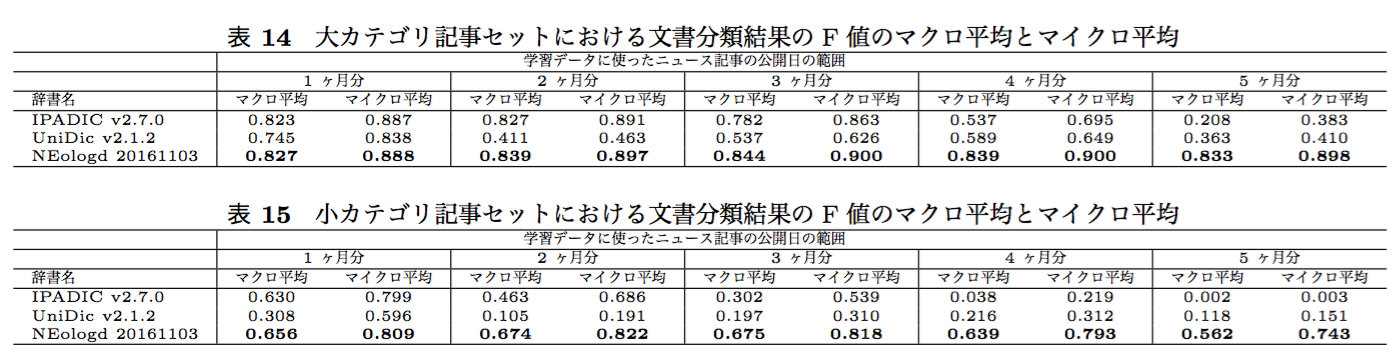
表14の評価データを大カテゴリに分類した場合の結果も、表15の評価データを小カテゴリに分類した場合の結果も、どちらも mecab-ipadic-NEologd は他のすベての辞書による結果との符号検定の結果の P 値≦ 0.001 と なっており有意水準 0.001 で有意でした(一応言及しておきます)。
要するに、mecab-ipadic-NEologd を使う以外には何も工夫をしていないし、パラメタも最適に調整していない状態なのに、結構良い結果が出ている、ということが伝われば大丈夫です。
小カテゴリの方の結果を眺めると、IPADIC を素朴に使った場合に驚くほど悪い結果が出るときには、この表の様な状態になっている可能性がありそうだと分かります。 データ量が 1 ヶ月分の時は mecab-ipadic-NEologd との差はそれほど大きくありませんが、学習データ量を増やした際の性能の低下速度がとても速いです。形態素単位で分割すると、何故ここまで性能が低下するのかについての詳細な考察は今後行う必要があります。
mecab-ipadic-NEologd を使用した場合は学習データの量を 3 ヶ月分まで増やしても分類性能は低下しませんでした。
しかし、4 ヶ月分以上になるとデータ量に比例して性能が徐々に下がりました。マクロ平均がより早く低下することから、mecab-ipadic-NEologd が対応できていない分野がいくつも存在すると考えられます。2016 年 6 月から 7 月にかけてその分野に関する記事が多数出現したのでは無いかと考えていますが、その確認は今後行います。
2 つの実験から、新語や未知の複合名詞を見出し語として mecab-ipadic-NEologd に追加し続けたことによって、新しいニュース記事から、より高次元で疎なベクトルを作成することができ、そのおかげで辞書に見出し語を追加しない場合や、極めて短い形態素に区切る場合と比べて、分類器の性能劣化の速度を緩やかにできたのでは無いか、と考えられます。
詳細はNL研の論文に書きました
上記の実験は、2016年12月21日・22日に都内で開催された「情報処理学会 自然言語処理研究会(NL研と呼ばれている)」で私が発表した内容を、より簡略化したものです。
この発表では辞書そのものよりも、辞書を生成するためのシステムとその運用について重点的に述べています。
(15) [NL] 17:25 – 17:55
単語分かち書き用辞書生成システム NEologd の運用 — 文書分類を例にして —
○佐藤敏紀・橋本泰一(LINE)・奥村 学(東工大)ブログなので、実験におけるエラー分析の概要などをバッサリと省略して書きましたけど、ご容赦下さい。今後、より詳細な実験や真面目な考察がまとまり次第、別の発表する機会で公表させていただきます。
まとめ
この記事では mecab-ipadic-NEologd の解説と、それを使っておこなったニュース記事の分類実験の結果を通じて、「mecab-ipadic-NEologd は便利で、安心して最新版をご利用頂ける」とお伝えしたいと思いました。
週2回以上も更新され、固有表現や複合名詞や未知語が速やかに登録される OSS な辞書は他にありませんので、その観点からもオススメです!!mecab-ipadic-NEologd は単体で使用するのではなく、その他の辞書(IPADICやUniDicなど)による解析結果と混ぜて使うことで、より便利に使えますので様々な使い方をお試し下さい。mecab-ipadic-NEologd の最新情報は Twitter の #neologd などに流れますので、こちらもチェックをお願いします。
最後に、弊社ではインターネットが大好きな自然言語処理エンジニアを募集しております。ご応募お待ちしております。
明日の木曜日はAdvent Calendar最終回、愛甲さんによる「セキュリティエンジニアからみたUnityのこと」です。お楽しみに!!!!!!