
جام مقدس جداسازی قطعات در مقیاس رک ، همانطور که آمپر روز دوشنبه گذشته به Data Center Knowledge گفت ، پارچه ای خواهد بود که ارتباط بین DRAM و اتوبوس های سیستم قفل شده را قطع می کند. پردازنده ها را می توان به صورت “سطل” جمع کرد ، DPU یا IPU به داخل کابینت جمع می شوند و آرایه های ذخیره سازی را می توان با شبکه های فوق العاده سریع جلو زد ، در صورتی که فقط حافظه سیستم را می توان در آرایه های جمع شده جمع کرد.
چهارشنبه ، این هدف تا حدودی مشهودتر شد ، زیرا دو نفر از مبتکران اصلی در محاسبات Express Express Link (CXL) ، طراح فرستنده و گیرنده اتصال AnalogX مستقر در تورنتو و Aix-en-Provence ، طراح اتصال PLDA مستقر در فرانسه (تا همین اواخر همکار در پروژه های یکدیگر) هر دو توافق کردند که توسط تولید کننده افسانه ای حافظه ، رامبوس خریداری شود. این معامله خصوصی خواهد بود و پیش بینی می شود در Q3 2021 بسته شود.
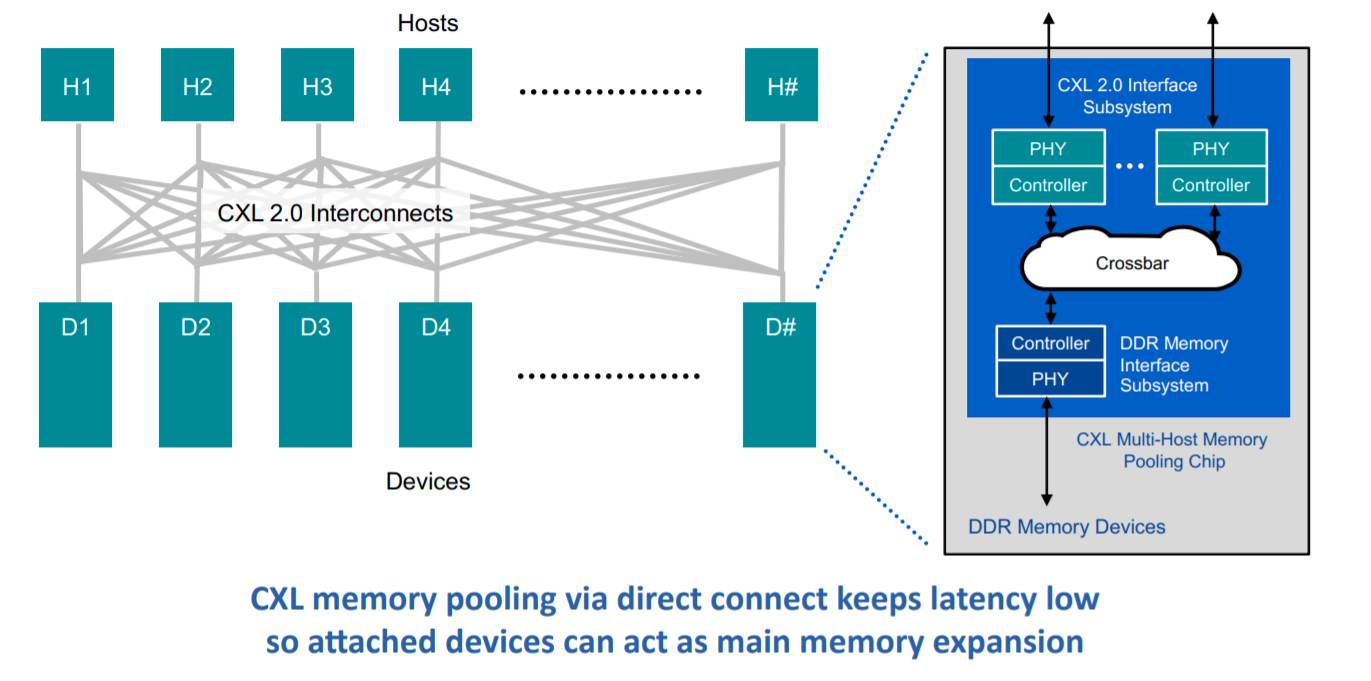
CXL – یک استاندارد فناوری که اولین بار توسط اینتل پشتیبانی می شود – روشی در حال توسعه برای ساخت سیستم حافظه مشترک است. از یک گذرگاه توسعه استفاده می کند که اجزای سازنده می توانند به عنوان PCI Express رفتار کنند ، اما به روشی که چندین م componentsلفه در سیستم نه تنها می توانند مقادیر را در همان حافظه بخوانند و بنویسند ، بلکه طرح اتصال به ترتیب نوشته های مختلف مرتب می شود. درست مثل اینکه یک پایگاه داده باشد (فقط خیلی سریعتر). ویژگی اصلی در اینجا است انسجام حافظه نهان.
اگر با معماری به سبک رایانه شخصی (که هنوز هم برای طراحی سرور مرکز داده بسیار کاربردی است) آشنا باشید ، می دانید که پردازنده های مرکزی مستقیماً به حافظه سیستم (معماری غالب DDR) می پردازند ، در حالی که پردازنده های گرافیکی از حافظه اختصاصی خود استفاده می کنند (معمولاً GDDR ) صنعت شتاب دهنده در حال گرم شدن است ، زیرا گوگل تصمیم می گیرد که یک واحد پردازش تانسور (TPU) که به وظایف یادگیری ماشین اختصاص داده می شود. همین هفته ، اینتل از مفهوم پردازنده زیرساختی مستقل (IPU) استقبال کرد ، که چندین دهه در زمینه طراحی سیستم اتوبوس گسیخته است.
بنابراین نیاز به یکی دیگر از آرایه حافظه اختصاصی چیزی است که طراحان سیستم ترجیح می دهند از آن اجتناب کنند.
اینتل ممکن است در حال حاضر بالای این مشکل باشد ، زیرا خود را برای اعلامیه های بیشتر در فضای سیستم های جداگانه آماده می کند. حرکت امروز رامبوس می تواند باعث پیشرفت سریع آن شود و به آن دسترسی مستقیمی به فناوری مورد نیاز برای ساخت یک کنترلر موثر CXL 2.0 می دهد.
در واقع ، PLDA و AnalogX به تازگی طراحی موفقیت آمیز چنین کنترل کننده ای را اعلام کرده اند. در تاریخ 2 ژوئن ، دو شرکت طراحی خود را قادر به کاهش تأخیر دسترسی به حافظه تا 12 نانو ثانیه (ns) اعلام کردند.
این به عملکرد شبیه DRAM نزدیکتر است ، اما کاملاً در آنجا وجود ندارد. حافظه پرسرعت DDR3 امروز در یک گذرگاه معمولی تأخیر حدود 7 ns را ایجاد می کند.
یک مقاله سفید اخیر Rambus [PDF] مزایای استخر را از این طریق توضیح می دهد:
با اتصالات مستقیم با تأخیر کم ، دستگاه های حافظه متصل می توانند از DDR DRAM برای ایجاد حافظه اصلی میزبان استفاده کنند. این کار می تواند به صورت بسیار انعطاف پذیر انجام شود ، زیرا یک میزبان قادر است به ظرفیت یا تعداد بیشتری از دستگاه های مورد نیاز برای مقابله با حجم کار خود دسترسی داشته باشد. مطابق با اشتراک گذاری rides ، حافظه به صورت “در صورت لزوم” در اختیار میزبان قرار می گیرد و باعث بهره وری و بهره وری بیشتر از حافظه می شود. و این معماری گزینه ای را برای تأمین حافظه اصلی سرور برای بارهای اسمی فراهم می کند ، نه بدترین حالت ، با امکان دسترسی به استخر در صورت نیاز برای بارهای با ظرفیت بالا ، مزایای بیشتر برای TCO [total cost of ownership].
اگر این روند همانطور که سازندگان تجهیزات محاسباتی مرکز داده پیش بینی می کنند ادامه یابد ، ممکن است به زودی فرمولهایی که برنامه ریزان ظرفیت برای تأمین فضا و منابع خنک کننده استفاده می کنند ، بر اساس ظرفیت محاسبه سرورهای جداگانه ، لازم است به طور کامل جایگزین شوند.
اخبار روز چهارشنبه درست به زمان اجلاس سالانه طراحی رامبوس می رسد که قرار است امسال ، در 23 و 24 ژوئن برگزار شود.