به عنوان حرکت با دستگاه آموزش و تحقیقات همچنان ادامه دارد و ما همچنان به شنیدن در مورد تحقیقات در حال انجام پیشرفت و شاید مهم ترین پردازش زبان طبیعی (NLP) پیشرفت در 12 ماه گذشته بود و چیزی به نام برت. صنعت ترجمه معاملات با کلمات و در نتیجه هر فن آوری پیشرفته است که باعث بهبود قابلیت تبدیل کلمات از یک زبان به زبان دیگر در نظر گرفته می شود مهم ترین و تاثیرگذار. بنابراین این تمایل وجود دارد که محل اختراعات جدید همیشه در ترجمه متن در صنعت. این گرایش نه همیشه حس و این پست تلاش خواهد کرد برای روشن کردن و توضیح برت در جزئیات به اندازه کافی برای کمک به خوانندگان در درک بهتر ارتباط و استفاده از این نوآوری در محدوده صنعت ترجمه.
آنچه که برت?
سال گذشته گوگل منتشر شد یک شبکه عصبی مبتنی بر تکنیک برای پردازش زبان طبیعی (NLP) قبل از آموزش به نام دو طرفه انکودر نمایندگی از ترانسفورماتور (BERT). در حالی که به نظر می رسد کاملا یک لقمه برت قابل توجه است و احتمالا حتی انقلابی گام رو به جلو برای ان به طور کلی. شده است وجود دارد بسیار هیجان در ان جامعه پژوهش در مورد برت چرا که آن را قادر می سازد تا پیشرفت های قابل توجهی در طیف گسترده ای از های مختلف ان ، قرار داده و برت به ارمغان می آورد پیشرفت های قابل توجهی به بسیاری از وظایف مربوط به درک زبان (NLU).
نکات زیر به ما کمک کند به درک برجسته فنی و نوآوری و رانده شده توسط برت :
- برت است که از قبل آموزش دیده در یک مجموعه زیادی از مشروح داده است که افزایش و بهبود پس از آن NLP وظایف. این قبل از آموزش گام این است که نیمی از سحر و جادو در پشت برت موفقیت. به این دلیل است که به ما آموزش یک مدل در یک متن بزرگ corpus, مدل شروع به انتخاب کنید تا بیشتر در عمق و صمیمی به درک چگونه این زبان کار می کند. این دانش است که چاقو ارتش سوئیس است که برای تقریبا هر ان کار. برای مثال یک برت مدل را می توان تنظیم به سمت کوچک داده ان وظیفه lآیک پرسش و پاسخ و تجزیه و تحلیل احساساتو در نتیجه قابل توجهی بهبود دقت در مقایسه با آموزش های کوچکتر مجموعه از ابتدا. برت اجازه می دهد تا محققان به دولت از-هنر نتایج حتی زمانی که بسیار کوچک آموزش داده ها در دسترس است
- کلمات مشکل ساز هستند زیرا بسیاری از آنها مبهم polysemous و مترادف. برت طراحی شده است برای کمک به حل مبهم جملات و عبارات است که ساخته شده تا تعداد زیادی و تعداد زیادی از کلمات با معانی متعدد.
- برت کمک خواهد کرد با چیزهایی مانند:
- نام نهاد تعیین.
- Coreference قطعنامه.
- پرسش و پاسخ.
- کلمه حس ابهامزدایی.
- خودکار خلاصه سازی.
- Polysemy قطعنامه
- برت یک مدل تک و معماری است که به ارمغان می آورد بهبود در بسیاری از وظایف مختلف است که قبلا امر نیاز به استفاده از چندین مدل مختلف و معماری.
- برت همچنین فراهم می کند یک مقدار بهتر متنی حس و در نتیجه افزایش احتمال درک قصد در جستجو. گوگل نام این به روز رسانی "بزرگترین جهش رو به جلو در پنج سال گذشته و یکی از بزرگترین جهش رو به جلو در تاریخ جستجو کنید."
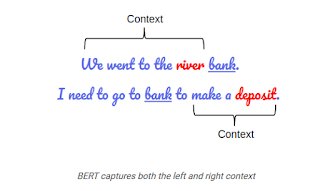
در حالی که برت یک بهبود قابل توجهی در چگونه کامپیوتر "درک" زبان انسان آن است که هنوز دور از درک زبان و متن در راه همان است که انسان انجام دهد. ما باید با این حال انتظار می رود که برت خواهد تاثیر قابل توجهی در بسیاری از درک ان متمرکز طرح های. به طور کلی درک زبان ارزیابی معیار (چسب) مجموعه ای از داده های مورد استفاده برای آموزش و ارزیابی و تجزیه و تحلیل ان مدل نسبت به یک دیگر. این مجموعه طراحی شده برای تست یک مدل را درک زبان و مفید برای ارزیابی مدل شبیه برت. به عنوان چسب نتایج نشان می دهد برت باعث می شود آن را ممکن است به بهتر انسان حتی در درک کارهایی که قبلا تصور می شود غیر ممکن است برای کامپیوتر به بهتر انسان است.
برای درک بهتر این, من به تازگی نشستم با SDL ان کارشناسان Dragos Munteanu و استیو DeNeefe. من از آنها سوال برای کمک به همه ما درک بهتر برت و آن تاثیر ممکن است در مناطق دیگر از فن آوری های زبان.
- شما می توانید در توصیف عبارت چه BERT است و به همین دلیل وجود دارد تا هیجان زیادی در مورد آن ؟
برت ترکیبی از سه عامل در یک راه قدرتمند. آن است که بسیار بزرگ توجه مبتنی بر شبکه عصبی معماری شناخته شده به عنوان "ترانسفورماتور Encoder" (ترانسفورماتور شبکه های ما بر اساس NMT 2.0 جفت زبان). یکی با استفاده از یک "پر از خالی" روش برای آموزش شبکه که در آن شما حذف کلمات به صورت تصادفی از یک پاراگراف و سپس سیستم تلاش می کند تا پیش بینی آنها. سوم آن است که آموزش در مقادیر عظیم زبانه متن معمولا به زبان انگلیسی. نیز وجود دارد انواع آموزش با فرانسه آلمانی چینی و حتی یکی از آموزش دیده با 104 زبان های مختلف (اما نه با موازی داده ها).
نتیجه قدرتمند نمایندگی از زبان در زمینه است که می توان به "نظریه" (سرعت اقتباس شده) برای انجام بسیاری از کارهای چالش برانگیز قبلا در نظر گرفته شده برای رایانه یعنی نیاز به جهان دانش و یا حس مشترک.
- برخی احساس می کنید که برت خوب است برای هر چیزی مربوط به ان اما آنچه خاص ان مشکلاتی که برت را حل کرده است ؟
برت و سایر مدل های مشابه (RoBERTa, OpenAI GPT XL-Net) هستند دولت از هنر در بسیاری از ان کارهایی است که نیاز به طبقه بندی و توالی برچسب زدن و یا مشابه موجب از متن به عنوان مثال نام نهاد به رسمیت شناختن, سوال, پاسخ, تجزیه و تحلیل احساسات. برت یک انکودر پس از آن هضم داده اما خود به خود آن را تولید نمی کند و داده ها. بسیاری از ان وظایف همچنین شامل داده های ایجاد کار (به عنوان مثال abstractive summarization ترجمه) و این نیاز به اضافی شبکه و آموزش بیشتر.
- من آگاه هستم که چندین برت الهام گرفته از طرح های در حال ضرب و شتم بشر خطوط بر چسب (به طور کلی درک زبان ارزیابی) آنلاین. آیا این به این معنی است که کامپیوتر ما را درک زبان است ؟
شبکه های عصبی یادگیری نقشه برداری از ورودی به خروجی با پیدا کردن الگوهای خود را آموزش داده است. عمیق شبکه های میلیون ها نفر از پارامترها و در نتیجه می توانند یاد بگیرند (یا "مناسب") کاملا الگوهای پیچیده. این است که واقعا آنچه را قادر می سازد برت به انجام به خوبی در این وظایف است. در نظر من این است که معادل آن به درک درستی از زبان است. وجود دارد چند مقاله و نظر قطعات که تجزیه و تحلیل این مدل رفتار در یک سطح عمیق تر, به طور خاص در تلاش برای ارزیابی نحوه اداره آنها پیچیده تر زبانی موقعیت و آنها نیز نتیجه گرفت که ما هنوز هم به دور از درک واقعی. صحبت از SDL تجربه آموزش و ارزیابی برت مبتنی بر مدل برای انجام وظایف مانند تمایلات تجزیه و تحلیل و یا پاسخ به پرسش ما تشخیص این مدل انجام تحت. با این حال آنها هنوز هم بسیاری از اشتباهات است که بسیاری از افراد هرگز را.
- اگر خلاصه سازی است و یک قدرت کلیدی از برت – آیا شما آن را ببینید ساخت راه خود را به محتوای دستیار قابلیت های که SDL به عنوان CA مقیاس برای حل سازمانی بزرگتر مشکلات مربوط به درک زبان?
خلاصه سازی یکی از قابلیت های حیاتی در کالیفرنیا و یکی از مفید ترین, در, را قادر می سازد مطالب درک است که ما هدف فراگیر. ما در حال حاضر انجام استخراجی summarization که در آن ما را انتخاب مرتبط ترین بخش از سند است. در به رسمیت شناختن این واقعیت است که افراد مختلف در مورد مراقبت از جنبه های مختلف مطالب ما اجرا تطبیقی استخراجی خلاصه سازی قابلیت. کاربران ما می توانید انتخاب کنید بحرانی عبارات مورد علاقه خاص به آنها و خلاصه تغییر خواهد کرد را انتخاب کنید بخش که بیشتر مربوط به آن دسته از عبارات.
روش دیگر این است که abstractive summarization که در آن الگوریتم تولید زبان جدید وجود نداشت در سند بودن خلاصه شده است. داده های قدرتمند خود نمایندگی ترانسفورماتور شبکه مانند برت هستند در یک موقعیت خوب برای تولید متن است که هر دو روان و مربوط به سند معنی است. در آزمایش های ما تا کنون ما را دیده اند و نه شواهد قانع کننده که abstractive خلاصه تسهیل مطالب بهتر درک.
- من را خوانده ام که در حالی که وجود دارد برخی از مزایای به تلاش برای ترکیب برت زبان مبتنی بر مدل به NMT سیستم; با این حال این فرایند به انجام این کار به نظر می رسید و نه پیچیده و گران قیمت در منابع از نظر. آیا شما می بینید برت تحت تاثیر قابلیت های آینده به NMT در نزدیکی و یا در آینده دور?
Pretrained برت مدل را می توان در راه های مختلفی برای بهبود عملکرد سیستم های NMT, اگر چه مختلف وجود دارد مشکلات فنی. برت مدل های ساخته شده در همان ترانسفورماتور معماری مورد استفاده در زمان دولت از هنر سیستم های NMT. بنابراین در اصل یک برت مدل می تواند مورد استفاده قرار گیرد یا به جای انکودر بخشی از NMT سیستم و یا برای کمک به مقداردهی اولیه NMT مدل پارامترهای. یکی از مشکلات این است که همانطور که اشاره کردید با استفاده از یک برت مدل را افزایش می دهد پیچیدگی محاسباتی. و سود برای MT هستند بنابراین دور نیست که قابل توجه; ابدا این نوع از مزایای که برت به ارمغان می آورد بر چسب سبک وظایف. با این حال ما همچنان به نگاه به شیوه های مختلف بهره برداری از دانش های زبانی رمزی در برت مدل های ما را MT سیستم های بهتر و قوی تر.
- دیگران می گویند که برت می تواند کمک به در حال توسعه NMT سیستم برای کم منابع زبان. هستند که قابلیت انتقال یادگیری از زبانه داده به احتمال زیاد به تحت تاثیر قرار توانایی ما برای دیدن بیشتر کم منابع زبان ترکیبات در مدت کوتاهی?
یکی از جنبه های برت است که مرتبط ترین در اینجا این است که ایده آموزش تضمینی است که می تواند به سرعت خوب تنظیم برای انجام وظایف مختلف است. اگر شما ترکیب این با مفهوم چند زبانه مدل شما می توانید تصور کنید که یک معماری/آموزش روش است که می آموزد و می سازد و مدل های مربوط به زبان های مختلف (شاید از همان خانواده) که پس از آن می توان تنظیم برای هر زبان در خانواده با مقدار کمی از موازی داده است.
- چه هستند برخی از قابلیت های خاص منابع و شایستگی که SDL است که شرکت را قادر به اتخاذ این نوع از فن آوری دستیابی به موفقیت سریع تر است ؟
گروه ما دارای تخصص در تمام مناطق درگیر در حال توسعه, بهینه سازی و استقرار ان فن آوری های تجاری برای استفاده از موارد. ما باید در سطح جهان محققان که به رسمیت شناخته شده در زمینه های مربوطه خود را و به طور منظم انتشار مقالات در کارشناسی کنفرانس.
ما در حال حاضر ساخته شده است یک تنوع از ان قابلیت استفاده از دولت از هنر و تکنولوژی: summarization نام نهاد به رسمیت شناختن, سوال, نسل, سوال, پاسخ, تمایلات تجزیه و تحلیل جمله تکمیل خودکار. آنها در مراحل مختلف در این تحقیقات به تولید طیف و ما همچنان به توسعه امکانات جدید.
ما همچنین تخصص در استقرار بزرگ و پیچیده یادگیری عمیق ، ما فن آوری طراحی شده است برای بهینه استفاده کنید یا Cpu یا gpu ها در هر دو 32 بیتی یا 16 بیتی حالت و ما درک می کنیم چگونه می توان کیفیت-سرعت تجارت آف برای تحقق موارد استفاده گوناگون از مشتریان ما.
تاریخ و زمان آخرین اما نه کم ما پرورش همکاری نزدیک بین تحقیقات مهندسی و مدیریت محصول. توسعه قابلیت های ان را که بتن ارزش تجاری به عنوان یک هنر آن را به عنوان یک علم و موفقیت تنها می تواند به دست آمده از طریق وسعت تخصص و همکاری.
tinyurlbitlyis.gdu.nuclck.ruulvis.netcutt.lyshrtco.de
مقالات مشابه
- شرکت صادرات و واردات کالاهای مختلف از جمله کاشی و سرامیک و ارائه دهنده خدمات ترانزیت و بارگیری دریایی و ریلی و ترخیص کالا برای کشورهای مختلف از جمله روسیه و کشورهای حوزه cis و سایر نقاط جهان - بازرگانی علی قانعی
- گشت مرزی پاسخ به پورتلند ناآرامی ها: ضلالت از ماموریت و یا ادامه ؟
- P. E. I. تحمیل محدودیت برای مسافران برای کمک به کنترل گسترش COVID-19
- شرکت صادرات و واردات کالاهای مختلف از جمله کاشی و سرامیک و ارائه دهنده خدمات ترانزیت و بارگیری دریایی و ریلی و ترخیص کالا برای کشورهای مختلف از جمله روسیه و کشورهای حوزه cis و سایر نقاط جهان - بازرگانی علی قانعی
- 'متاسفانه او با ما نیست': خانواده سوگوار یک پدر که رد و سپس درگذشت از COVID-19
- عینک شنا ساخته شده ساده - حتی کودکان شما هم می توانند این کار را انجام دهند
- ویرجینیا تفنگ محدوده می تواند بازگشایی — فرماندار تجاوز اقتدار خود را قاضی قوانین
- ما به اعطای عراق گاز چشم پوشی در حمایت از نخست وزیر جدید
- ده ها تن از افراد بی خانمان منتقل و پس از skid row پناهگاه گزارش شش coronavirus موارد
- صربستان تظاهرات اتحادیه اروپا شرح تسلا به عنوان معروف کروات